Amplify API - AppSync - CRUD (Create Read Update Delete)
AWS AppSync simplifies application development by letting you create a universal API to securely access, modify, and combine data from multiple sources. AppSync is a managed service that uses GraphQL so that applications can easily retrieve only the data they need.
With AppSync, you can build scalable applications, including those requiring real-time updates, using a range of data sources such as NoSQL data stores, relational databases, HTTP APIs, and native data sources with AWS Lambda. For mobile and web applications, AppSync also provides access to local data when devices go offline and syncs data when they reconnect to the Internet. In this case, the client can customize the order of conflict resolution.
Benefits:
Easy start and development in step with the business
Get started in minutes with your chosen IDE (e.g. Xcode, Android Studio, VS Code), and use the intuitive AWS AppSync or AWS Amplify CLI management console to automatically generate your API and client code. AWS AppSync integrates with Amazon DynamoDB, Amazon Aurora, Amazon Elasticsearch, AWS Lambda, and other AWS services, allowing you to build complex applications with virtually unlimited performance and memory that change based on your business needs.
Live Subscriptions & Offline Access
AWS AppSync provides real-time subscriptions to millions of devices and offline access to application data. Once the device is reconnected, AWS AppSync syncs only the updates at the time the device was disconnected, not the entire database. AWS AppSync offers customizable server-side conflict detection and resolution.
Unified and secured access to distributed data
Perform complex queries and generalizations across multiple data sources with a single network call using GraphQL. AWS AppSync makes it easy to protect your application data by using multiple authentication modes at the same time, and also allows you to determine the severity of the threat and perform granular access control at the data definition level directly from your GraphQL schema.
In this tutorial we will create a GraphQL API that interacts with a DynamoDB NoSQL database to perform CRUD (create, read, update, delete) operations.

Connecting the API plugin
amplify add api


schema.graphql
After the selected items, the GraphQL schema will open in amplify / backend / api / <datasourcename> / schema.graphql where we insert this model:
type Job @model @auth(rules: [{ allow: owner, ownerField: "owner", operations: [create, update, delete] }]) {
id: ID!
position: String!
rate: String!
description: String!
owner: String
}
This is a GraphQL schema. GraphQL Transform provides an easy-to-use abstraction that helps you quickly build back-end for web and mobile apps on AWS. With GraphQL Transform, you define your application's data model using the GraphQL Schema Definition Language (SDL), and the library handles transforming the SDL definition into a set of fully descriptive AWS CloudFormation templates that implement your data model.
When used in conjunction with tools such as Amplify CLI, GraphQL Transform simplifies the process of developing, deploying, and maintaining GraphQL APIs. With it, you define your API using the GraphQL Schema Definition Language (SDL) and then you can use automation to transform it into a fully descriptive cloud content pattern that implements the specification. GraphQL is an API specification. It is a query language for the API and a runtime for making those queries with your data. It shares some similarities with REST and is the best replacement for REST.
GraphQL was introduced by Facebook in 2015, although it has been used internally since 2012. GraphQL allows clients to define the structure of the data they require, and it is this structure that is returned from the server. Querying data in this manner provides a much more efficient way for client-side applications to interact with APIs, reducing the number of underfetching and preventing overfetching.
Learn more about GraphQL here
Let's go back to our diagram, where the main components of the GraphQL schema are object types, which is the type of object that you can retrieve from your service:
Jobis a GraphQL Object Type, that is, a type with some fields. Most of the types in your schema will be object types.id position rate description owner- fields in the Job type. This means that these are the only fields that can appear in any part of a GraphQL query that works with a Job type.Stringis one of the built-in scalar types - these are types that resolve to a single scalar object and cannot have sub-selections in a query. We'll look at scalar types later.String!- field is non-null, means that GraphQL promises to always give you a value when you request this field. In general, this is a required field.
Types
GraphQL comes with a set of default scalar types out of the box:
IntA 32-bit signed integer.Floatdouble precision floating point value.Stringis a sequence of UTF - 8 characters.Booleantrue or false.The
IDscalar type ID is a unique identifier, often used to retrieve an object or as a key for a cache. The identifier type is serialized in the same way as a string; however, defining it as an identifier means that it is not intended for human perception.
Directives
@ model- Object types marked with@ modelare top-level objects in the generated API. Objects marked with@ modelare stored in Amazon DynamoDB and can be protected with@ auth, linked to other objects with@ connection@ auth- Authorization is required for applications to interact with your GraphQL API. API keys are best used for public APIs. The @ auth object types annotated with @ auth are protected by a set of authorization rules that provide you with more controls than the top-level authorization in the API. You can use the @ auth directive to define object and field types in your project schema. When using the@ authdirective on object type definitions that are also annotated with@ model, all recognizers that return objects of that type are protected.
Other directives and details in official documentation.
Directive rules @auth
@auth( rules: [ {allow: owner, ownerField: "owner", operations: [create, update, delete]} ])
means that CREATE, UPDATE, DELETE operations are allowed only to the owner, and READ operations are allowed to all.
It's time to put it to the test! Therefore, we write the command in the console:
amplify mock api
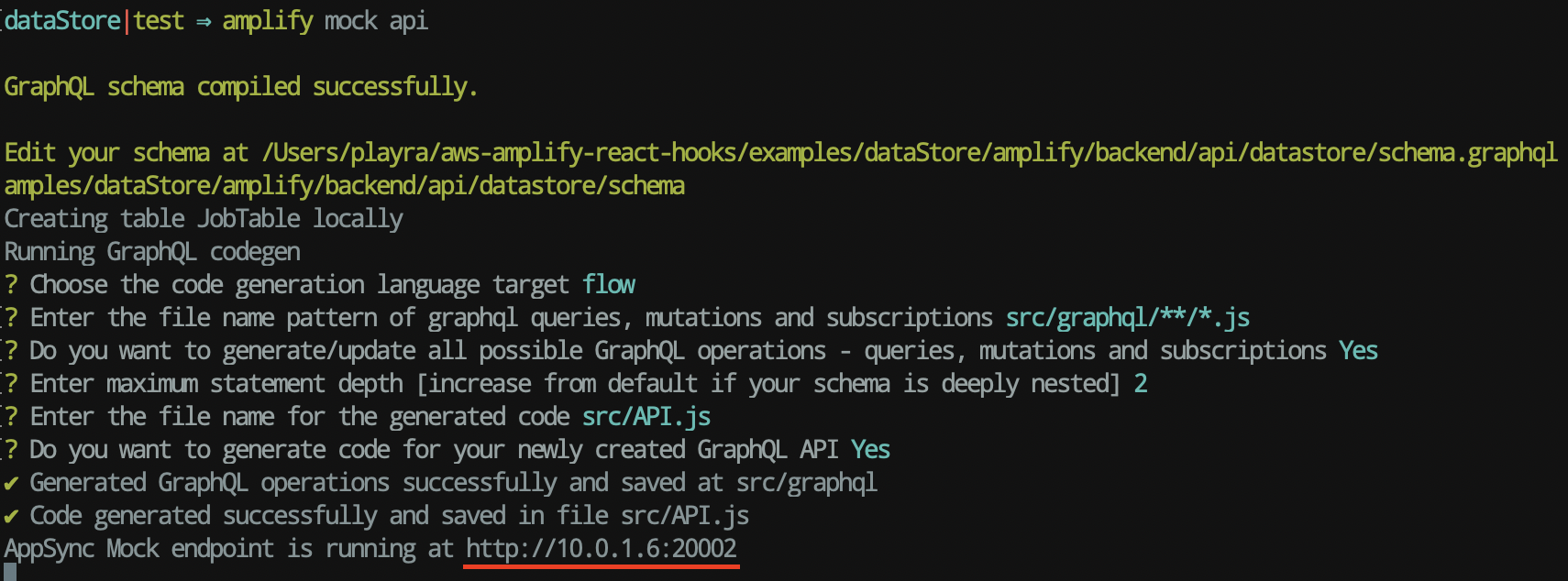
With this command, you can quickly test your changelog without having to provision or update the cloud resources you use at each step. This way, you can set up unit and integration tests that can run quickly without affecting your cloud backend.
Three pillars on which GraphQL stands:
Query (READ)
Simply put, queries in GraphQL are how you are going to query data. You get exactly the data you need. No more no less.
Mutation (CREATE UPDATE DELETE)
Mutations in GraphQL are a way to change data on the server and get the updated data back.
Subscriptions
A way to maintain a connection to the server in real time. This means that whenever an event occurs on the server and when that event is raised, the server will send the appropriate data to the client.
You can see all the available methods of our created API by clicking on the Docs (Documentation Explorer) in the upper right corner. The values are clickable, so all possible queries can be viewed.
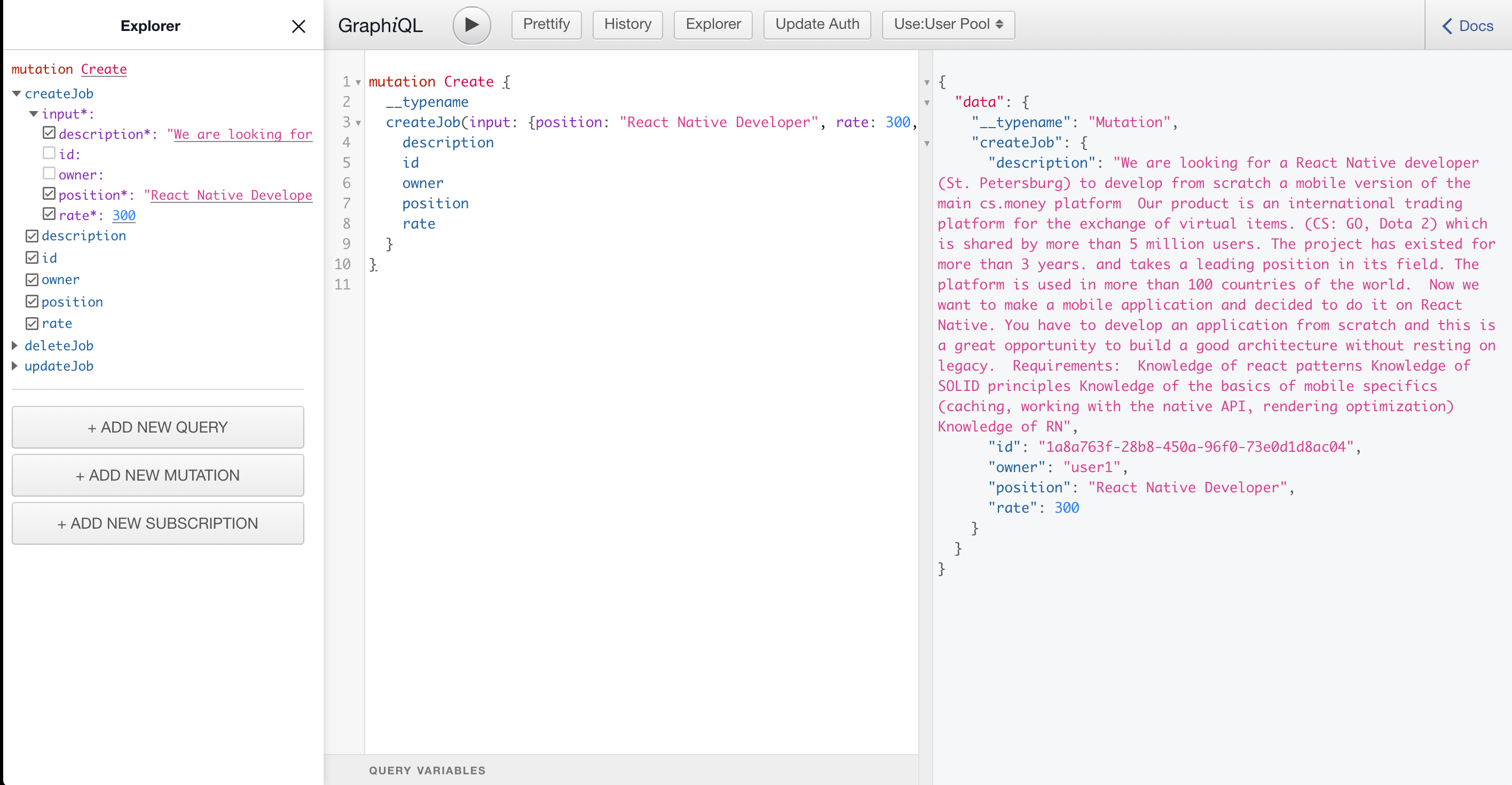
CREATE
We open our API at the address that issued (each has its own) result of the amplify mock api command and execute the CREATE request by pressing the play button.
mutation Create {
__typename
createJob(
input: {
position: "React Native Developer"
rate: 3000
description: "We are looking for a React Native developer (St. Petersburg) to develop from scratch a mobile version of the main cs.money platform Our product is an international trading platform for the exchange of virtual items. (CS: GO, Dota 2) which is shared by more than 5 million users. The project has existed for more than 3 years. and takes a leading position in its field. The platform is used in more than 100 countries of the world. Now we want to make a mobile application and decided to do it on React Native. You have to develop an application from scratch and this is a great opportunity to build a good architecture without resting on legacy. Requirements: Knowledge of react patterns Knowledge of SOLID principles Knowledge of the basics of mobile specifics (caching, working with the native API, rendering optimization) Knowledge of RN"
}
) {
description
id
owner
position
rate
}
}
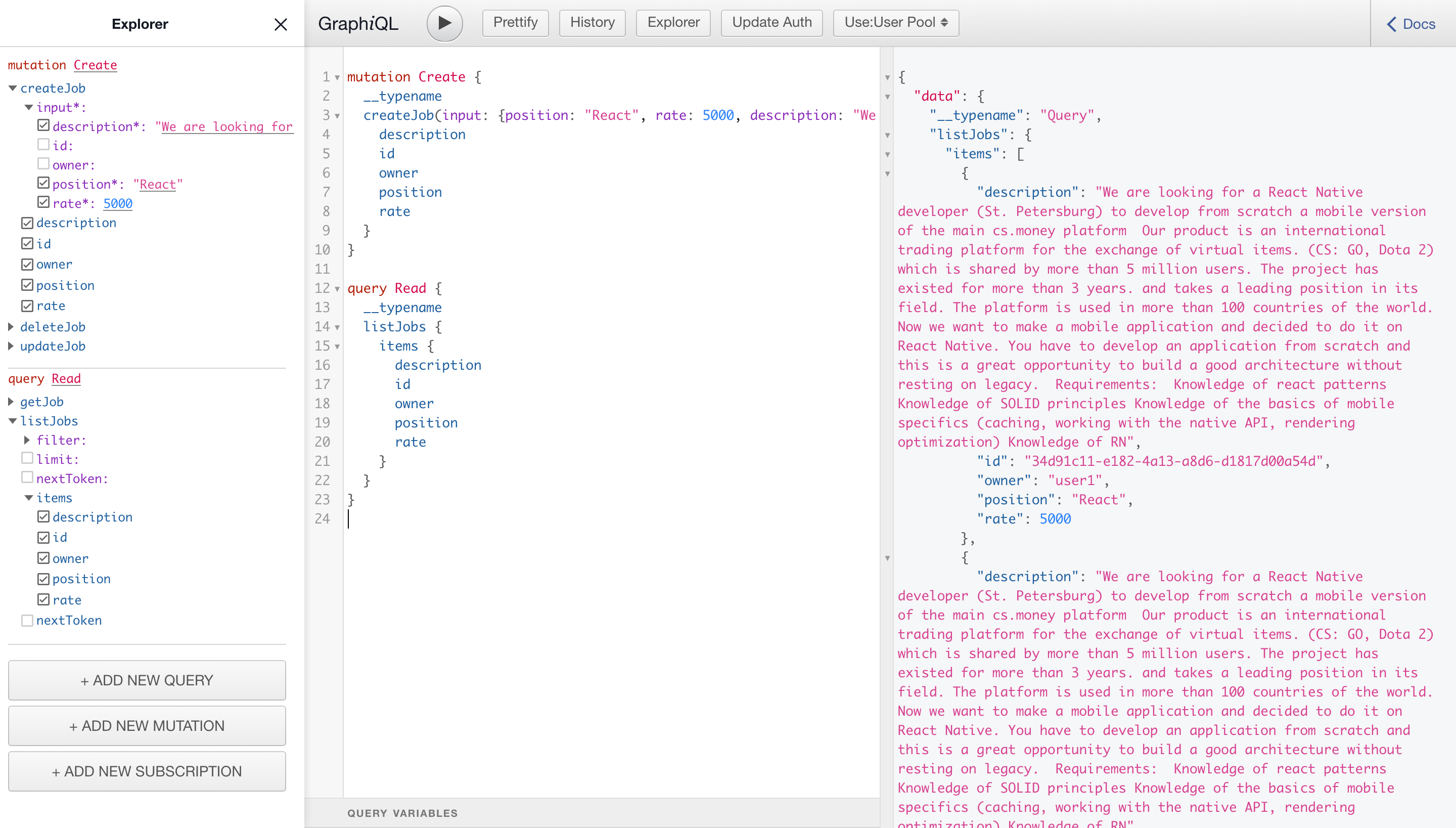
To consolidate the material, create some more vacancies.
READ
We get a list of all vacancies. Insert the request:
query Read {
__typename
listJobs {
items {
description
id
owner
position
rate
}
}
}
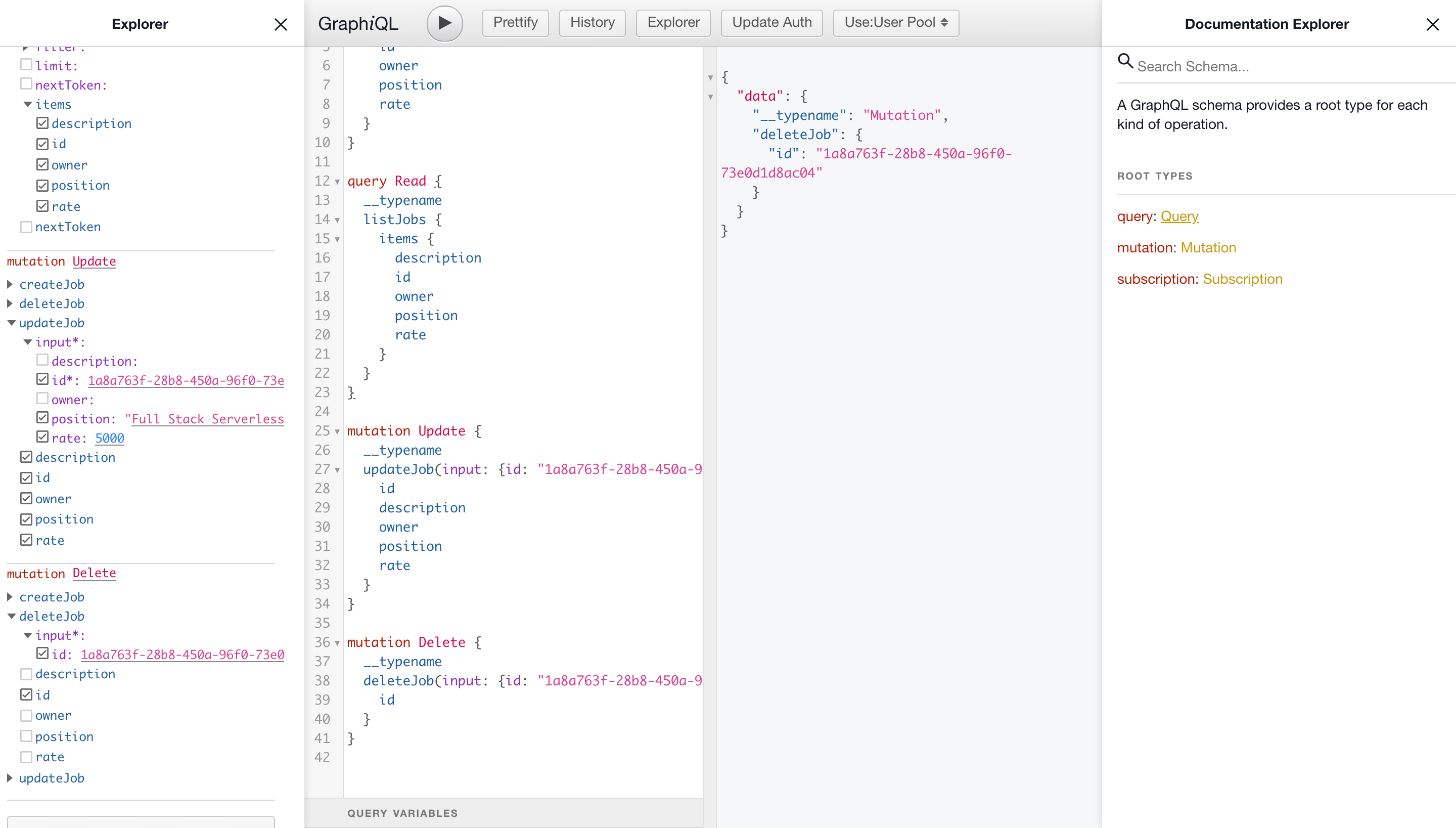
UPDATE
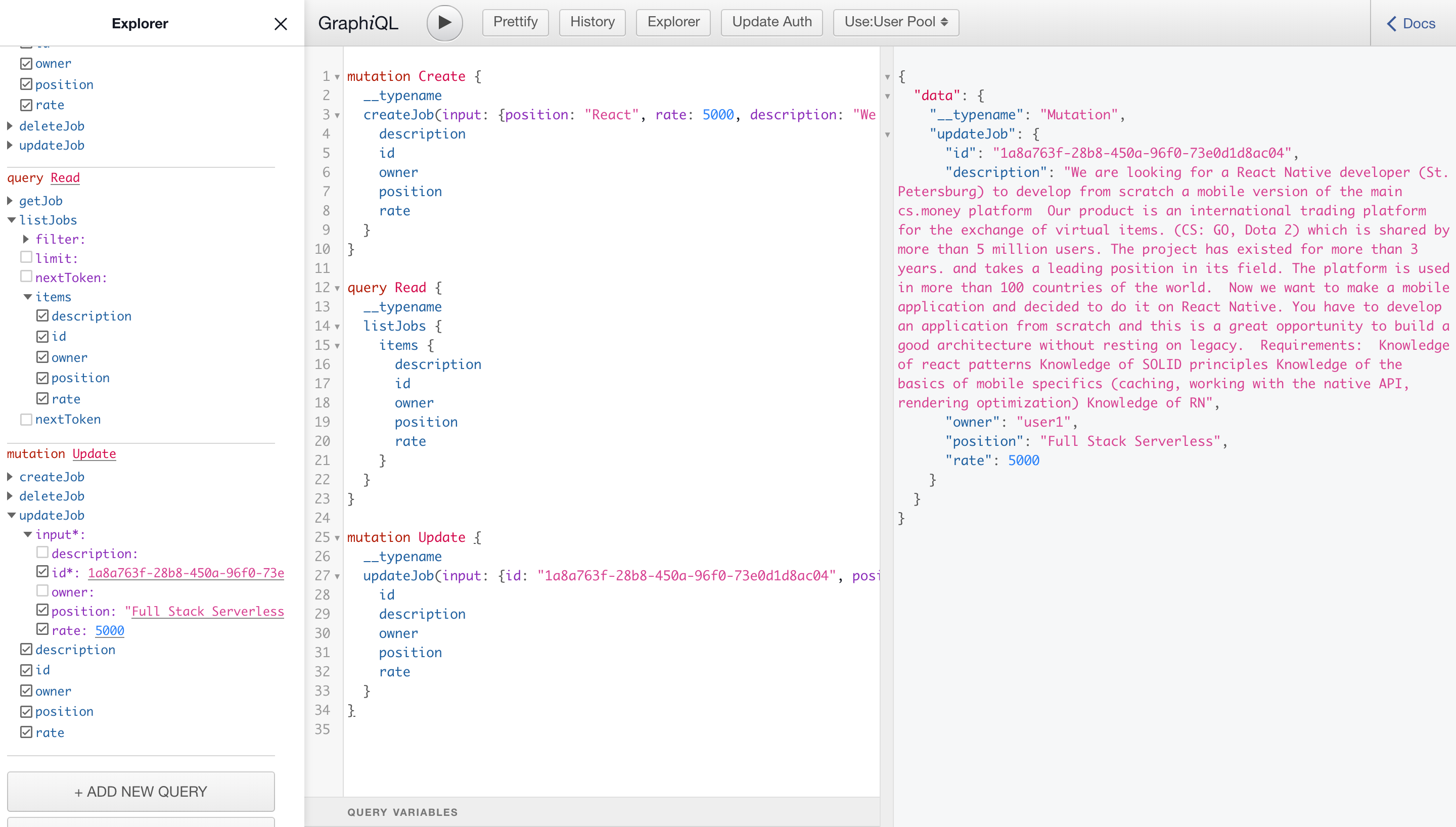
To update, we need to take the vacancy ID (be sure to enter your own, not from the example) and transfer it to this request with the changed data. For example, update the fields position and rate
mutation Update {
__typename
updateJob(input: { id: "1a8a763f-28b8-450a-96f0-73e0d1d8ac04", position: "Full Stack Serverless", rate: 5000 }) {
id
description
owner
position
rate
}
}
DELETE
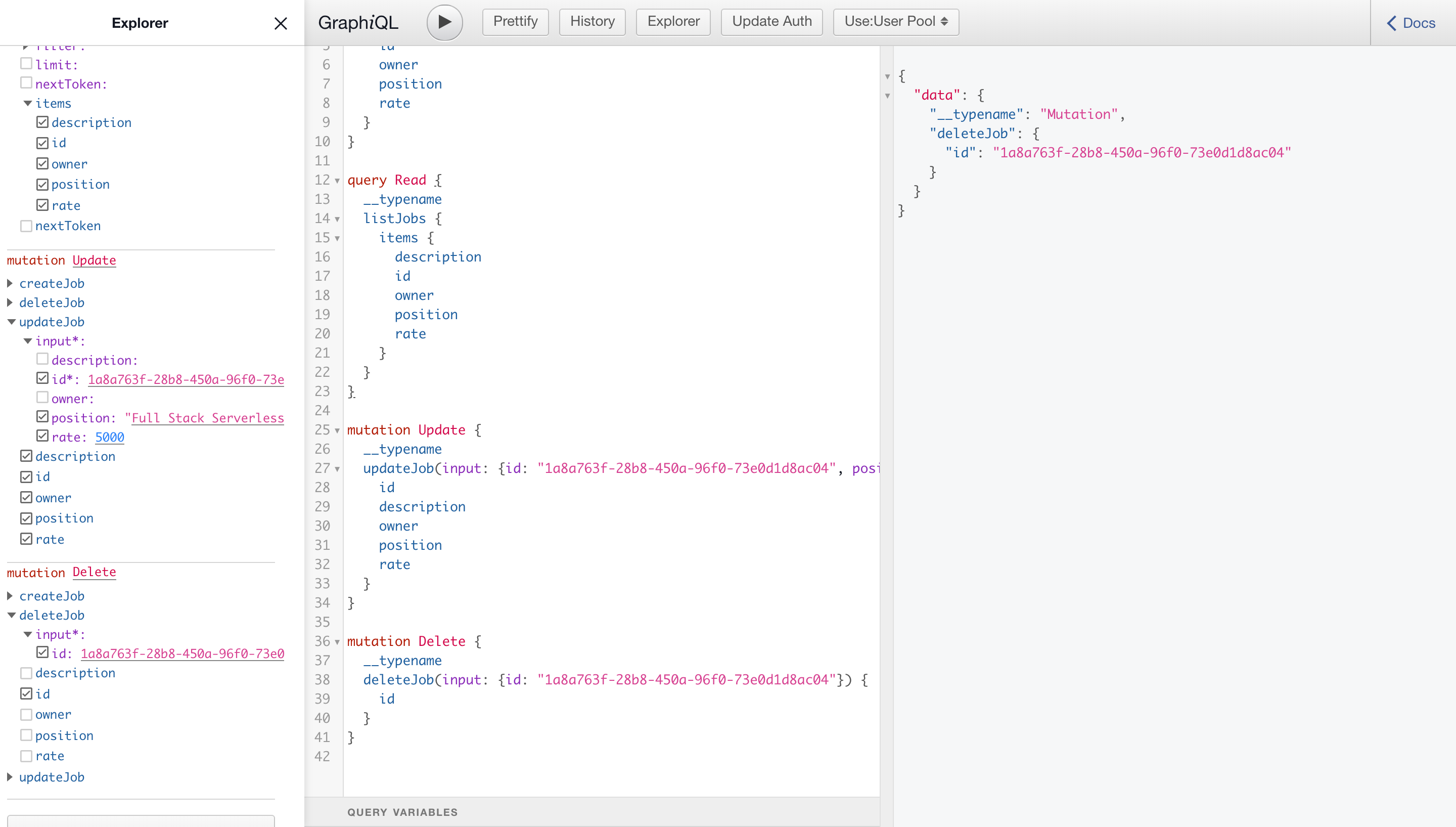
To delete, as in the case of the update, we need to transfer the vacancy ID (be sure to enter your own, and not from the example).
mutation Delete {
__typename
deleteJob(input: { id: "1a8a763f-28b8-450a-96f0-73e0d1d8ac04" }) {
id
}
}
Permissions
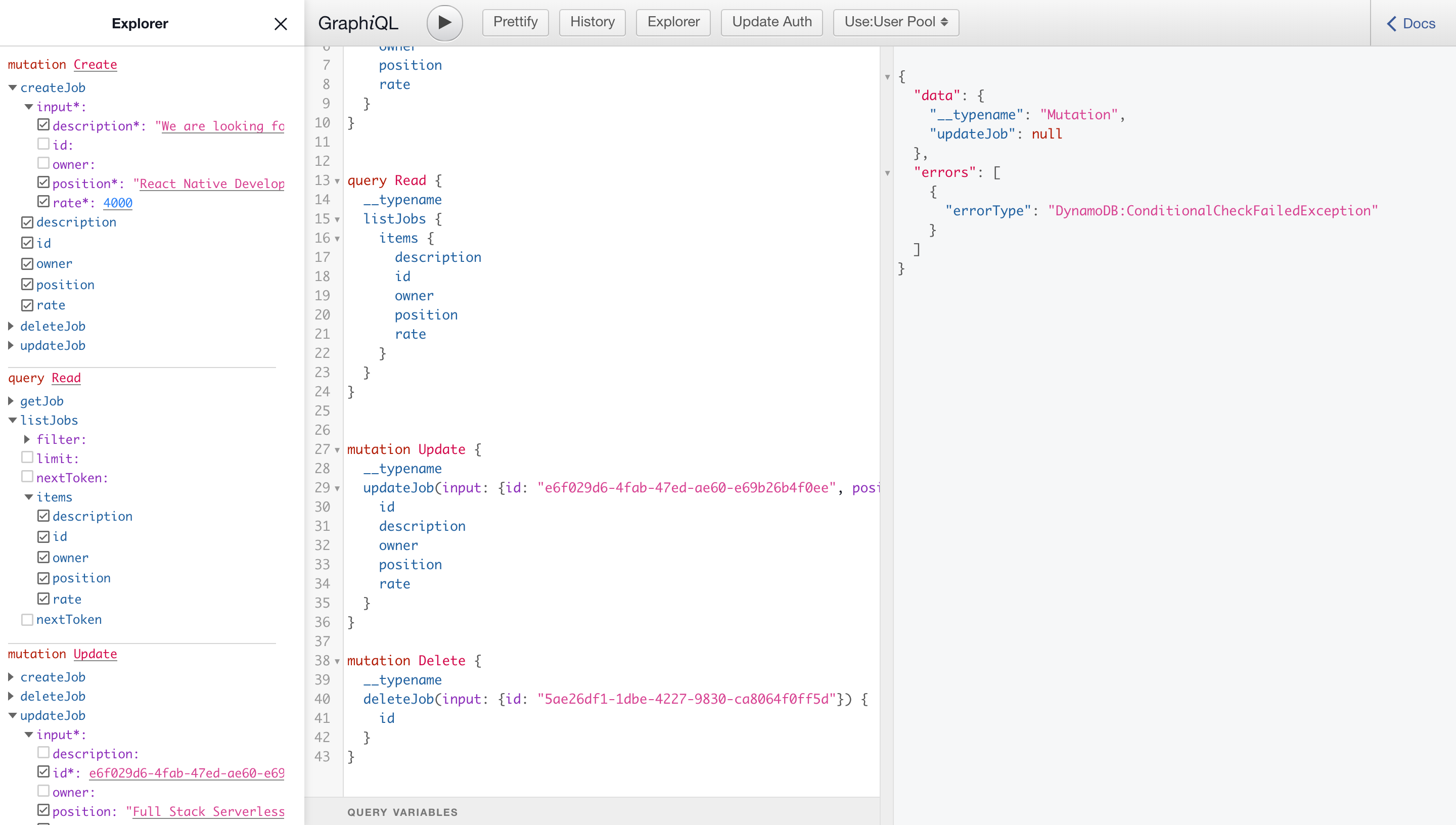
Now let's check if our rules work as we indicated in the scheme. Only the owner can update, delete, and create.
@auth( rules: [ {allow: owner, ownerField: “owner”, operations: [create, update, delete]}, ])
To change the user click on UpdateAuth in the main menu. Where we arbitrarily update Username and Email.
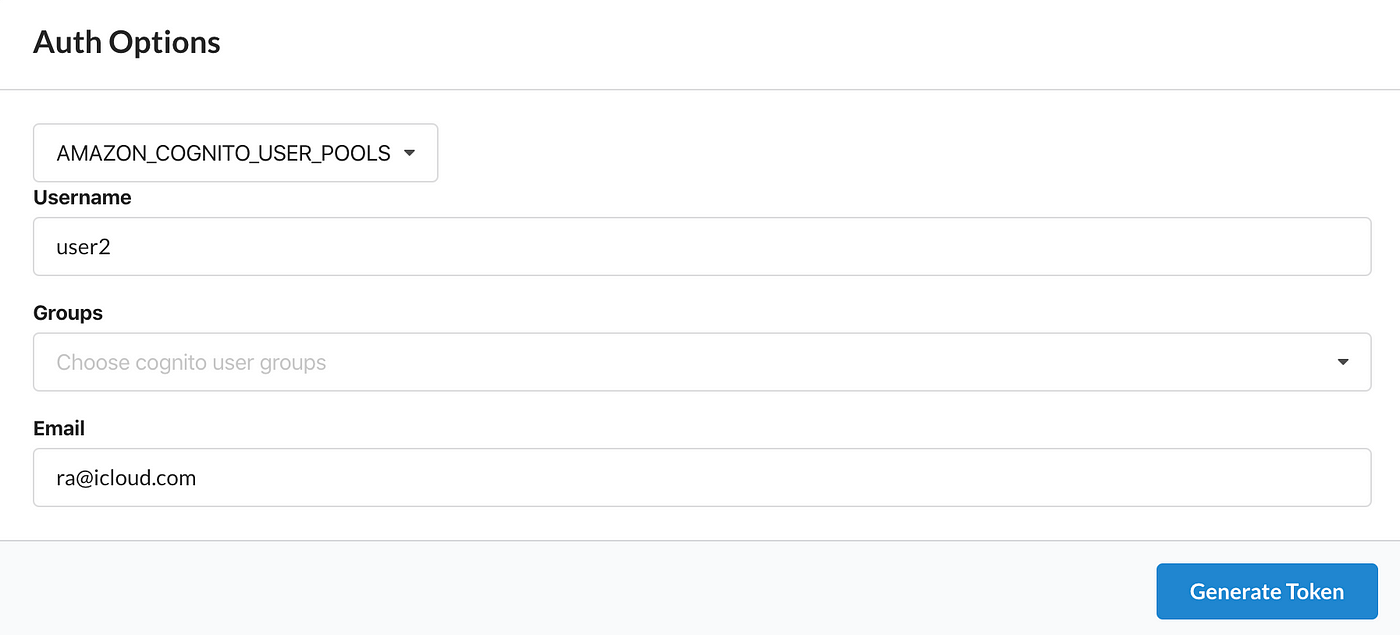
If we send a READ request, then it works, but if we send an UPDATE or DELETE request and get an error. The rules work, as required!
Now that we have tested the functionality of the API, we can publish it to the cloud with the command:
amplify push
After a few minutes, the model is uploaded to the AWS servers, so next we move on to the react native application.
